
應對AI時代挑戰,抓住AI時代機遇
我們致力於幫助企業做好數據工程和AI工程,提供成本最優、效果最佳的數據和AI解決方案。
企業實踐AI面臨的核心挑戰

數據基礎薄弱,難以支撐智能決策
缺乏結構化、成體系的業務數據,使得人工智能難以有效理解業務語境,限制模型效果與場景落地深度。

資源投入高,性價比難以平衡
通用型開源框架或公有雲方案在擴展性與定製化方面存在局限,數據存儲與算力消耗持續攀升,整體運營成本居高不下。

平台依賴嚴重,技術可控性不足
過度依賴外部系統或第三方組件,造成架構封閉、靈活性受限,既增加集成難度,又難以保障最終應用效果與投入產出比。
統一流處理與湖倉分析架構
我們的架構旨在打破傳統數據孤島。透過與 Kafka 協議完全相容的 API,我們能夠從各種數據來源(包括日誌、物聯網設備、資料庫變更等)高效擷取數據。數據流入我們基於雲端物件儲存(如 AWS S3)構建的高效能流儲存核心。該系統不僅追求極致的性能成本,更致力於構建開放的、低成本的大容量數據存儲和索引,最終無縫地為AI大腦提供數據服務。
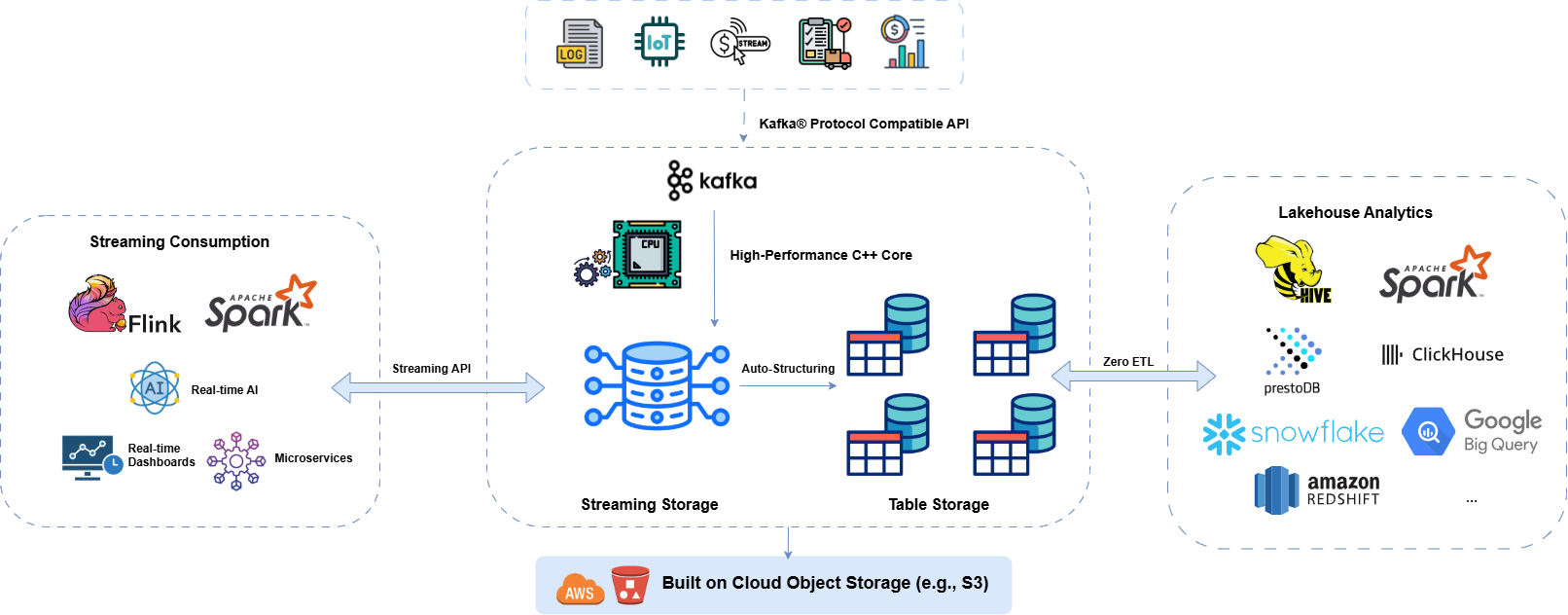
原生支持實時計算框架,驅動業務在線智能化
通过标准流式接口,系统可灵活对接 Apache Flink、Apache Spark 等主流流处理引擎,高效支撑实时 AI 推理、业务监控看板及高并发微服务等应用场景,助力构建响应迅速的智能系统。
無需繁重 ETL,即刻啟用分析能力
平臺使用開放型數據格式,可無縫對接多種查詢分析平臺,省去複雜的數據抽取與轉換流程,實現秒級數據可用,顯著加快洞察與決策效率。
方案優勢

靈活的場景支持
高度彈性,能夠靈活適配低延遲響應與高吞吐處理兩類場景。
系統具備高度彈性,能夠靈活適配低延遲響應與高吞吐處理兩類場景。通過參數配置即可實現運行模式的動態切換,無需複雜操作,便於運維與調整,滿足多樣化的大規模數據計算需求。

高效的開發和運維工具
無縫集成主流可視化工具,實現數據的圖形化呈現,輔助業務快速洞察。
平台可無縫集成主流可視化工具,實現實時數據的圖形化呈現,輔助業務快速洞察。同步內嵌性能監控與日誌追踪模塊,具備異常預警機制,有效提升系統穩定性並降低運維複雜度。

簡易使用
提供基於 SQL 的流式數據開發能力,兼容多種計算模型。
提供基於 SQL 的流式數據開發能力,兼容事件時間語義、會話窗口與無界數據窗口等多种计算模型,支持流数据间及与静态数据的实时关联。内置自动化优化引擎,在保证高性能的同时降低开发门槛,支持直观的数据分析与报表构建,助力业务快速上线。

卓越的計算引擎支撐複雜任務
內建流式計算引擎,支持以標準 SQL 語言構建實時處理任務。
平台內建流式計算引擎,支持以标准 SQL 语言构建实时处理任务,兼容事件驱动模型、会话统计与长时间窗口等多种流处理场景,可实现流数据与静态数据之间的动态联动。系统配备智能优化模块,在保障高并发性能的同时,显著降低开发与维护的技术门槛,支持业务快速上线与可视化数据输出。

廣泛適配多樣數據形態
可處理多種異構數據類型,適用於各類數據的統一管理與分析。
系統可處理多種異構數據類型,具備面向大規模數據量的高效存儲能力和靈活計算框架,適用於結構化、半結構化乃至非結構化數據的統一管理與分析。
平滑銜接現有系統架構
支持大批量歷史 SQL 腳本與存儲邏輯的無縫遷移。
平台支持大批量歷史 SQL 腳本與存儲邏輯的無縫遷移,無需大幅改造即可接入新環境,同時支持與現有報表工具無縫銜接,大幅降低遷移風險,提升切換效率。

數據持久性與系統可用性並重
可實現秒級故障轉移與自動恢復,有效保障系統連續運行。
可實現秒級故障轉移與自動恢復,有效保障系統連續運行與數據完整性,滿足關鍵業務的高穩定性要求。

多層級安全機制守護數據資產
實現集中統一的訪問與資源管理策略,支持細粒度權限控制。
平台實現集中統一的訪問與資源管理策略,支持細粒度權限控制與用戶隔離機制,確保計算集群運行環境免受惡意風險干擾,全面保障企業級數據安全。